Our this article is on this research paper .
Credit : Bo YU

What we will do ?



Credit : Bo YU

What we will do ?
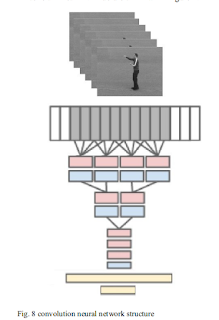
We build a set of human behavior recognition system based on the convolution neural network constructed for
the specific human behavior in public places.
(i) : Firstly, video of human behavior data set will be segmented into images, then
we process the images by the method of background subtraction to extract moving foreground characters of body. (ii). Secondly,
the training data sets are trained into the designed convolution neural network, and the depth learning network is constructed
by stochastic gradient descent.
(iii). Finally, the various behaviors of samples are classified and identified with the obtained
network model, and the recognition results are compared with the current mainstream methods. The result show that the
convolution neural network can study human behavior model automatically and identify human’s behaviors without any
manually annotated trainings.
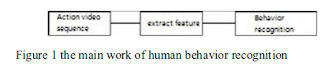
Human behavior recognition is mainly divided into two
processes: the identification and understanding of human
behavior feature extraction and motion .

This algorithm is mainly composed of three parts,
1. Video pretreatment, 2. Model training 3. Behavior recognition part.
In the video preprocessing part,
firstly the original behavior of video preprocessing, using
block updating background subtraction method to achieve
target detection, two value image motion information is
extracted, then the image input channel convolutional neural
network, through the iterative training parameters of the
network, to construct a model for convolution Behavior
Recognition . Finally, you can use this network to identify
human behavior .




Implementation Code on Github : Code